Faire un RAG (La génération augmentée par récupération) sur une documentation
🔍 RAG Personnel — Moteur de Recherche Documentaire Local
Projet perso réalisé pendant une période creuse au travail, par curiosité et envie d’explorer le stack NLP/LLM de bout en bout.
Objectif
Construire un système de Retrieval-Augmented Generation (RAG) from scratch, capable de répondre à des questions en langage naturel à partir d’un document PDF et cela sans dépendre d’une API externe comme OpenAI.
Architecture
PDF uploadé
│
▼
Chunking (RecursiveCharacterTextSplitter)
│ - chunk_size : 512 tokens (tokenizer HuggingFace)
│ - chunk_overlap : 10%
│ - déduplication automatique des chunks
▼
Embeddings (intfloat/multilingual-e5-small)
│ - modèle multilingue, léger, adapté FR/EN
│ - normalisation cosine
▼
Vector Store FAISS
│ - similarité cosine
│ - top-30 docs récupérés
▼
Reranking (FlashRank — ms-marco-MiniLM-L-12-v2)
│ - reclassement des 30 docs → top-5 pertinents
▼
Génération (Mistral-7B-Instruct-v0.3)
│ - quantisation 4-bit (BitsAndBytes nf4)
│ - prompt structuré avec template chat
▼
Réponse en français, sourcée par document
Stack technique
| Composant | Outil |
|---|---|
| Chargement PDF | LangChain PyPDFLoader |
| Chunking | RecursiveCharacterTextSplitter (HuggingFace tokenizer) |
| Embeddings | intfloat/multilingual-e5-small (SentenceTransformers) |
| Vector Store | FAISS (Meta) |
| Reranking | FlashRank — ms-marco-MiniLM-L-12-v2 |
| LLM | Mistral-7B-Instruct-v0.3 (quantisé 4-bit, BitsAndBytes) |
| Orchestration | LangChain |
| Visualisation embeddings | PaCMAP + Plotly |
| Environnement | Google Colab (GPU T4) |
Points techniques notables
- Chunking token-aware : taille des chunks calculée avec le vrai tokenizer du modèle d’embedding (pas juste en caractères), pour coller exactement à la fenêtre contextuelle du modèle.
- Pipeline retriever + reranker : deux étapes de sélection — récupération large (top-30) puis reranking croisé (top-5) pour maximiser la pertinence sans sacrifier le recall.
- Quantisation 4-bit : Mistral 7B tourne en mémoire GPU limitée grâce à
BitsAndBytesConfig(nf4 + double quant + bfloat16). - Prompt engineering en français : template structuré avec instruction système explicite pour obtenir des réponses sourcées et concises.
- Visualisation de l’espace d’embedding : projection 2D via PaCMAP pour observer la distribution des chunks et la position de la requête utilisateur dans l’espace vectoriel.
Ce que j’ai appris
- Le chunking est critique : un mauvais découpage casse la pertinence du retrieval bien plus que le choix du LLM.
- Le reranker change vraiment la donne sur des corpus avec du bruit : passer de top-30 brut à top-5 rerankés améliore nettement la qualité des réponses.
- La quantisation 4-bit rend les LLMs 7B accessibles sur GPU modeste (Colab T4) avec une perte de qualité négligeable en usage Q&A.
- RAG ≠ magie : la qualité de la réponse finale est bornée par la qualité du document source et la pertinence des chunks récupérés.
Limites & pistes d’amélioration
- Pas de gestion de l’historique conversationnel (pas de mémoire entre les questions)
- Interface en console uniquement — une UI FastAPI/VueJS serait le next step logique
- Pas de persistance du vector store entre les sessions Colab
- Évaluation de la qualité des réponses non formalisée (pas de métriques RAGAS)
- Modèle d’embedding monolithique — tester des modèles plus grands (
multilingual-e5-large) ou spécialisés métier
Résultats
Voici un exemple de prompt effectuée sur la documentation de notre SIRH, question à propos des affectations et le RAG est capable de générer une réponse juste.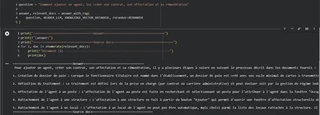

Développeur backend et DevOps avec 4 ans d’expérience en conception et déploiement de systèmes en production. J’ai travaillé sur des APIs REST, des pipelines de données et de l’automatisation CI/CD sur environnements conteneurisés (Docker, GitLab CI).
À l’aise sur C#/.NET, Python et PostgreSQL, j’interviens aussi bien sur le code que sur l’infrastructure — Ansible, Linux, monitoring.
Curieux des architectures microservices et du cloud Azure, je cherche un environnement technique exigeant où backend et DevOps se rejoignent.